
Recall from last time that we are trying to formalize phonology in terms of events (e, f, g, … .; points in abstract time), distinctive features (F, G, … ; properties of events), and precedence, a non-commutative relation of order over events (e^f, etc.). So far, together this forms a directed multigraph.
Inspired by a challenge from Greg Hickok, we’ll see how far we can get with those things without assuming explicit constructs such as sets of features constituting segments (viz subgraphs, more on this in a later post). We will try to avoid falling victim to the pitfalls cautioned against by Kazanina, Bowers & Idsardi 2017 by allowing events to have multiple properties (but we won’t bother collecting up such properties into sets either). Another way to put this point might be to say that we will attempt to cast segments as an emergent phenomena, arising out of features and order (oooh, that sounds so much better). We picked events, features and precedence for inclusion in the model precisely because they are substantive (admittedly, the points in time are pretty abstract), and provide a reasonable starting point for effectual interfaces to action and perception.
Special shit we need:
- #: an event such that ∀ e NOT e^# (yes, this entails NOT #^#)
- %: an element such that ∀ e NOT %^e (yes, NOT %^%)
- $: an empty element, see below. (Think juncture or instantaneous $ilence.)
# codes the beginning of time. (Not the Big Bang, just the abstract time under consideration in the current “workspace”.) % codes the end of time. (And I can’t bring myself to search for a Big Bang Theory quote.) # and % are always available. (I.e. in every workspace instance, see below. We’re building toward MERGE for workspaces. Ideally MERGE(π1,π2) is just the simple union of events, features and relations in both workspaces. But there’s no way it’s quite that simple.)
Another piece of substance that we might want to include is logical relationships among properties. We believe that some of these are universal, but some could also be induced by the learner and so could vary across languages. In particular, for now, we will include the basic feature co-occurrence restrictions and dimensional organization from Avery & Idsardi 1999 (A&I). (In a later post we’ll back off on this and see what being more permissive can buy us.) In the present context this means a couple of things. First, we include in the model the substance of the agonist/antagonist organization of the features (where a NAND b = NOT (a AND b), showing that I [wji] have been disparaging NAND for too long [fn: NAND and NOR are the only logical primitives that alone form a complete basis for the binary logical functions]):
(1) NANDs
- [spread] NAND [constricted]
- [stiff] NAND [slack]
- [raised] NAND [lowered]
- [high] NAND [low]
- …
Again, we see this as an empirical claim about phonology. If a good use for e.g. [high, low] events can be found then these conditions should be dropped. (And this is the sort of thing that we will explore later.) These are well-formedness conditions on phonological representations, and would govern rules//laws such that all rules/laws have to obey (1); (1) counts as part of the theory of “possible phonological rule/law”. How they manage to obey (1) is a matter for investigation.
Second, there are statements like IF F THEN G, meaning ∀ e IF Fe THEN Ge. (We don’t use the usual symbolic logic symbol for implication, →, because we also want to do graph operations as rules which will also use →. Another common symbol for implication, ⊃, is also used in set theory, so it has similar problems. So we’ll just spell it out.) Therefore, UG has statements like the following:
(2) IF-THENs
- IF [spread] THEN [GW]
- IF [GW] THEN [Laryngeal]
- ...
If we want to go the whole way to capturing the “bare dimensions” in the A&I framework (and at least one of us does), then we would also have statements like:
(3) XORs
- IF [GW] THEN [spread] XOR [constricted]
Given (1), could use OR here instead as F XOR G = (F OR G) AND (F NAND G). (3) would hold at the interface to the motor system but only there, i.e. no bare [GW] sent to the motor system, but bare [GW] is a possible representation in LTM (see A&I) or from the auditory system (= “there was something funky with the voice quality, but I’m not sure what”). This allows for special kinds of underspecification. Anthropomorphizing, a simple [GW] event on its way to the motor interface doesn’t yet know if its [spread] or [constricted] but it will be one or the other (called completion in A&I).
So far, we believe that this approach is broadly consistent with Jardine 2016. In our terms, Jardine adds another temporal relation (association) between events, we could notate that as e|f, indicating that e is associated to f. (On the “meaning” of association lines see Coleman and Local 1991, Sagey 1986, in the present context we could understand it as weak synchronization, “at about the same time”, recall Saberi & Perrott 1999). In that case there might also be universal restrictions on the combination of these two relations, something like ∀e,f IF e|f THEN NOT e^f AND NOT f^e. But given things like loops in time, this question is not nearly as simple as it first appears. Taking a minimalist position on this question, we will not include | here (but think about ASL again).
To get theories like Mielke 2008, just start with a different set of features, ones that denote whole “segments,” e.g. [ʊ]e, and then invent/discover/define/select classificatory properties like [round]:
(*4) IF [u] OR [ʊ] OR [o] OR … THEN [round]
Since we’re not going to adopt Mielke’s approach either, we’ve put * in front of 4 to mean that we’re not including it in our model (using the * is actually us trying to trick syntacticians into reading along). Obviously, you could turn such statements around also, IF [round, high, back, ATR, …] THEN [u], but it’s not clear to us what work we would do with [u] if we’ve got the features already. For circuit fanatics, (4) implies a disjunctive relationship between “primary” and “secondary” percepts; if features come “first” then it’s a conjunctive coding in the “second layer” instead. (We're sure the brain does both kinds of things.)
This brings us to an important point, we have not said anything about how many fneurons (features, properties) an event can have. We could include into the theory statements that make events as simple as possible, meaning that phonological representations would be maximally “scattered”, i.e. have a maximal number of events because each event would have at most one feature. The statement that would do this is:
(*5) ∀ F, G such that F ≠ G, F NAND G
Statement (5) has an important property, it’s a monadic second order formula because it is quantifying over properties. This is obscured because we wrote it in a "pointfree" style (the term is from Haskell), so let’s restate it making the event variable clear:
(*6) ∀ e ∀ F, G such that F ≠ G, Fe NAND Ge
(alternatively, ∀ e ∀ F, G IF [F, G]e THEN F = G)
We are quantifying over two different kinds of things, events and monadic properties, and the distinctness criterion (F ≠ G) is over properties, not events (which could be construed extensionally as the set of events Fe and the set of events Ge, but we will resist this interpretation and see properties and functions as first-class, as in Haskell).
We think that Theory(*6) is an interesting idea to pursue, but we won’t include (*6) here either (we’re fickle like that). That means that events can have multiple properties for us.
Properties in either the articulatory and auditory system can certainly overlap in time. If such “bindings” are recognized by, say, the perceptual system, that information could be conveyed into the phonology as a single event with multiple properties, e.g. [front, round]e. In passing we note that what the phonology receives from perception can be incomplete or distorted in all sorts of ways, but that the phonology trudges on to LTM anyway, despite occlusion (phoneme restoration effects), tinnitus, temporally reversed speech, and so on.
Consequently, we believe that one aspect of the phonological computation is to construct and deconstruct complex events, that is, to be able to split [front, round]e into [front]e, [round]f, fission, and vice versa (fusion), i.e. between (7) and (8) in either direction:
(7)

(8)

To do this we will almost certainly need a derivative relation on events, which is similar to the | we ascribe to Jardine. In a configuration like (8) we would say that e || f (“e is parallel to f”). (This will have to be generalized somewhat, something like a^e AND a^f AND NOT e^f AND NOT f^e.) If we do this generally in a language, then we could possibly capture the effects of line fusion in Government Phonology (Kaye, Lowenstamm and Vergnaud 1985). Another example of something like this might be Korean, in which all fricatives are strident, so we could fuse all parallel strident and fricative events. The net effect of this could be to impair the ability to detect (or possibly even to stably represent) non-strident fricatives. While we’re at this, if a rule can look for an environment like (8) then it’s probably also the case that a learning algorithm could examine such configurations to look for pairs of features that often occur in parallel, to find correlations or to learn event fusion/fission processes.
We return now to $, which we will define as an event without any properties, abstract silence or abstract juncture, a virtual pause. This is mostly for notational convenience, but it could turn out to be used as a basis for some segmentations. For example, sometimes the precedence statements that flow in from the perceptual system will form a bipartite graph between (groups of) events. That is, there will be events a,b,c and x,y,z such one cluster of elements mutually precede the other cluster:
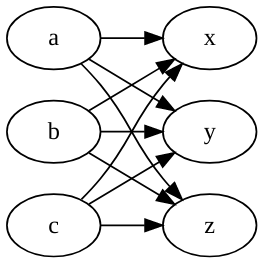
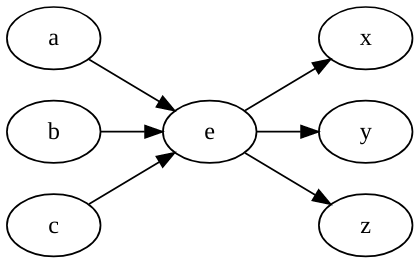
The left-hand graph is the graph K3,3, and is one of the two identifiers for non-planar graphs (the other being K5). That is, no graph containing K3,3 can be represented in two dimensions without crossing lines. Perhaps in such cases a $ event e is inserted to establish planarity. (Though why abstract planarity would be important here is not at all clear.) Depending on how common this situation is, this could “chunk” events, or provide alignment possibilities to guide LTM access.
We could add a clock, and thereby make a timing tier, but we won’t do that either for now. (But we think that such things will ultimately play an important role, see Gallistel & King 2009, and Giraud & Poeppel 2012. The auditory system does have a couple of endogenous clocks, see below.)
If you want to bring SPE back (we are repressing our inner Justin Timberlake here…) then you will need to:
- add [+F] synonyms for every [F]
- add all the [-F] definitions
(IF NOT [+F] THEN [-F] since SPE didn’t allow underspecification), - constrain temporal relations to be linear
(∀ a, b, e IF a^e AND b^e THEN a=b; IF e^a AND e^b THEN a=b) - constrain temporal relations to be complete
(∀ e ∃ a, b such that e = # OR e = % OR a^e^b)
Definitions for things like [αF] are left as an exercise for the reader. Although we like SPE, we won’t do this either.
Also we will include substance to the extent that it will allow for the identification of the articulator-free (manner) features. We’ll assume here that they are privatively coded [stop], [trill], [fricative], [liquid], [approximant], and that these interface to degrees and kinds of innervation to the articulators (i.e. a full ballistic gesture with [stop]). These, along with [nasal] are the landmarks of Stevens 2000 (see also various work by Carol Espy-Wilson and her colleagues), and constitute a proposal for a coarse-coded phonological “primal sketch” (Poeppel & Idsardi 2012). Given that we can have events with multiple properties, we can have events like [stop, Coronal] which would ultimately execute a full closure by the tongue blade. We can also if we want combine the insights of Clements and Rubach on affricates as strident stops with Steriade’s aperture theory. In such cases an event [stop, fric, Coronal, lateral] could be split into two events [stop, Coronal]^[fric, Coronal, lateral] to interface with motor control. (For those wanting mutually exclusive coding of manner features, i.e. *[stop, fric] = [stop] NAND [fric], just drop the [fric] feature from the “abstract” starting representation for the affricates.)
Finally, in order to interface with the dual timescale analysis being performed by the auditory system (Poeppel 2003, Giraud & Poeppel 2012), we will allow events which indicate syllables, σe. These events as they come out of the auditory system are innervated along a relatively slower time scale, in theta band (~ 4-8 Hz). The featural elements, like [spread], will be modulated by low gamma band oscillations (~ 20-40 Hz). Together (along with delta band) these form an endogenous clock (see Gallistel and King 2009) which permits the identification of precedence relations inside perception. It is also almost certainly the case that auditory streaming (Bregman 1990) affects the ability to identify precedence relations. Telling that a single neuron displayed an on-off-on pattern (and therefore concluding that ∃ x, y Fx^Fy) is easier than recognizing Fx^Gy for elements across streams, Fink, Ulbrich, Churan & Wittmann 2006. Is this enough by itself to induce “reflective” tier effects in the phonology? Would something like this make tier effects exogenous to the model (the perceptual input to the phonology is just more likely to include x^y statements within a stream)? We don’t think that there are easy answers to these questions.
Given how little specification that we have given to the model, there are few limits on what we can compute with it at the moment. But we are sure that this gives us enough “wiggle room” to capture the observations about linearity, invariance, and biuniqueness in Chomsky 1964.
We want to emphasize here that we do agree with SFP that the computation procedures within phonology are a complex, composed function, which is decomposable into simple functions, though here they are graph-theoretic operations (which are called transductions in that literature) on the events (nodes), properties (features) and precedence relations (links) in the phonological graph. Again, this is like Raimy 2000 without a timing tier, and Autosegmental Phonology without pre-defined tiers or association lines; just let precedence statements be stated between any pair of events, which might have any number of properties.
Next time: Dogs and cats
No comments:
Post a Comment